Understanding Association Rules
QuantMiner manipulates two main elements: ASSOCIATION RULES and DATA.
DATA
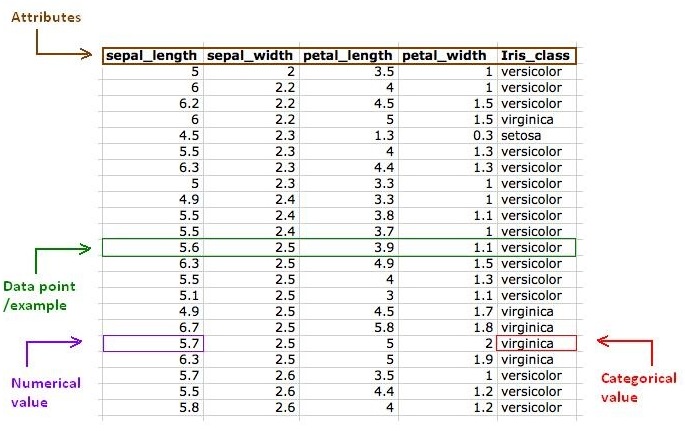
QuantMiner works on flat tables or spreadsheets where the columns are the attributes and the rows are the examples/records/data points on which the exploration will be done.
We can distinguish 2 kinds of attributes:
- Categorical: its values belong to a predefined set.
Example: The attribute Iris_class may have one of the 3 possible values {setosa, versicolor, virginica}
- Numerical: numbers belonging to a given domain not necessarily countable (e.g. real values).
Example: The attribute sepal_length has as domain [4.3, 7.9]
Here is an example of a dataset (Iris flower data set - UCI Machine Learning Repository Irvine, CA: University of California, School oh Information and Computer Science, http://www.ics.uci.edu/~mlearn/MLRepository.html):
ASSOCIATION RULES
An association rule is an expression C1 -> C2, where C1 and C2 express conditions on the attributes describing data points in the dataset.
Example: petal_length in [3.5; 4.7] -> Iris_class = versicolor
Meaning that:
"If the petal length is between 3.5 and 4.7 then the iris class is versicolor".
For categorical attributes, we try to discover special relationships between values.
For quantitative attributes, we try to discover ranges that play an important role.
A rule comes along with 2 quality measures: support and confidence.
The support :
It is the proportion of examples (data points/records) in the dataset satisfying the rule (both condition and consequence).
For a rule A -> B, the support is an estimation of p(A et B) = probability of having jointly A and B.
In the previous example petal_length in [3.5; 4.7] -> Iris_class = versicolor (support = 41 27%)
The confidence:
This measure assesses the strength of the rule.
In the dataset, we compute the proportion of examples satisfying the consequence among those satisfying the condition.
For a rule A -> B, confidence gives an estimation of p(B | A) = probability of having B knowing that we have A.
Example: petal_length in [3.5; 4.7] -> Iris_class = versicolor (confidence = 97%)
"Among the examples having a petal length in [3.5; 4.7] , 97% belong to the versicolor iris class".
ASSOCIATION RULE MINING
1. The user defines 2 thresholds, minimum support and minumum confidence.
2. The tool will test all possible rules and keep only the strongest ones.
For a rule with ONLY categorical attributes, the idea is to keep only the rules satisfying the minimum support and confidenc thresholds.
For a rule with at least one numerical attribute, that is a "quantitative association rule", the idea is to find the ideal intervals giving the best rule.
3. The number of rules generated can be very large, especially if the minimum support and minimum confidence thresholds chosen are low. Powerful sorting functions exist in QuantMiner to help the user exploring the results.
INTERPRETATION OF THE DIRECTION OF AN ASSOCIATION RULE
It is important to understand the difference between the rules A -> B and B -> A. It is often when there is no equivalence that the rules are interesting.
Consider the 2 following rules extracted from the Iris dataset:
support = 47 (31%) , confidence = 92% : Iris_class = versicolor -> petal_length in [3.3; 4.9]
support = 41 (27%) , confidence = 97% : petal_length in [3.5; 4.7] -> Iris_class = versicolor
Changing the direction of the rule modifies the intervals of the quantitative attributes along with the support and confidence.